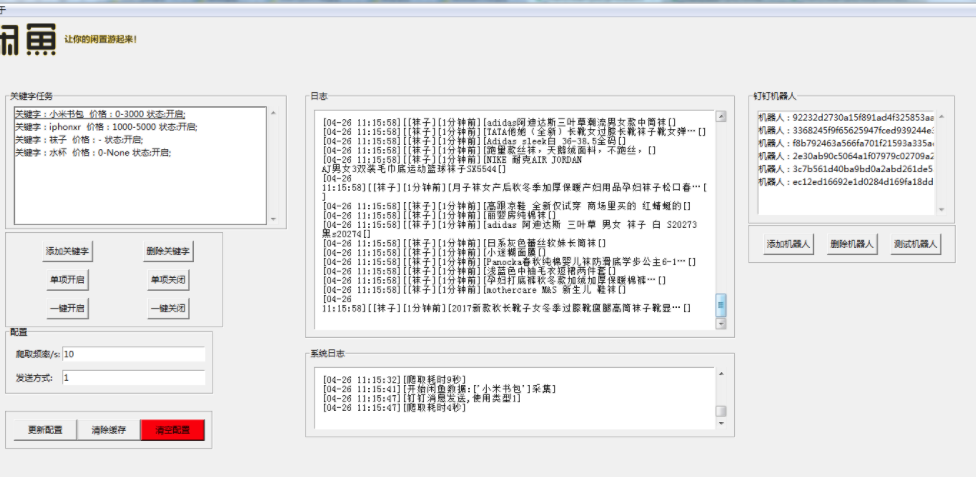

爬取思路
闲鱼网站原关键字直接搜索地址关闭。
经过查找,找到能搜索关键字的链接https://s.2.taobao.com/list/?q=关键字&page=2&search_type=item&_input_charset=utf8
经过多次爬取发现闲鱼并没有太多的反爬虫验证,索性连ua都不用给。【2019-08-07在之前爬取频率过多接口失效】目前只能做异步方式参考
闲鱼只能爬取某一个关键字商品前100页面。想要获取所有数据的思路:100页的数据量100x20=2k条左右,全部商品有200k,爬取商品总数量,按照地区分级爬取,如果分级后仍然大于2k,继续分地级。
只提供思路,并未实现


操作csv
在存储的过程中发现编码出现了问题。使用utf_8_sig解决。
pyquery解析数据
pyquery解析商品数据返回可迭代的对象。
pyquery可以根据class,id,div的属性进行解析。
异步爬取
核心使用异步请求的方式传送门README
异步爬取
核心使用异步请求的方式传送门README
项目部分代码.py
具体项目在另外的仓库,文件太大没有搬运
更新使用方式、7-25日 项目仍然能继续运行 接口失效后,应该不能爬取,只能作为练习思路学习
结果对比
单线程爬取时间
异步爬取时间
忘了截图*100次请求大概用了6-8s
运行环境
python3.5
requirements.txt
版权声明
文章来源: https://www.uihtm.com/python/15685.html
版权说明:仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。我们非常重视版权问题,如有侵权请邮件(44784009#qq.com)与我们联系处理。敬请谅解!